
대회명 : Regression of Used Car Prices
https://www.kaggle.com/competitions/playground-series-s4e9
Regression of Used Car Prices
Playground Series - Season 4, Episode 9
www.kaggle.com
- 대회 설명
다양한 속성을 기반으로 중고차 가격을 예측한는 대회
- 평가 방식
평균 제곱근 오차(RMSE)
- 수상작 구현
https://www.kaggle.com/code/hoon0303/mse-mae-autogluon
MSE/MAE + Autogluon
Explore and run machine learning code with Kaggle Notebooks | Using data from multiple data sources
www.kaggle.com
특징 : used_cars.csv 라는 데이터를 추가적으로 사용함
from autogluon.tabular import TabularPredictor
import warnings
warnings.filterwarnings("ignore")
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
import re
import lightgbm as lgb
from lightgbm import log_evaluation, early_stopping
from catboost import CatBoostRegressor, Pool
from xgboost import XGBRegressor
import random
from sklearn.svm import SVR
from sklearn.metrics import mean_squared_error
from sklearn.model_selection import KFold
from autogluon.tabular import TabularPredictortrain = pd.read_csv(f'{data_path}/train.csv')
test = pd.read_csv(f'{data_path}/test.csv')
Original = pd.read_csv(f'{data_path}/used_cars.csv')
- 데이터전처리
- Original 데이터의 milage, price 독립변수의 데이터 타입이 train,test와 다르기 때문에 이를 위한 작업 필요
# 정규표현식 사용을 통한 변환
Original[['milage', 'price']] = Original[['milage', 'price']].map(
lambda x: int(re.sub(r'[^\d]', '', x))) # 숫자가 아닌 문자를 빈문자로 대체
train.drop(columns=['id'], inplace=True) # 식별자 제거
test.drop(columns=['id'], inplace=True)
train = pd.concat([train, Original], ignore_index=True)from datetime import datetime
def extract_features(df):
"""
차량 데이터에서 연식, 주행 거리, 브랜드 정보를 기반으로 새로운 특성을 생성
"""
current_year = datetime.now().year # 현재 연도를 동적으로 생성
# 차량의 나이 계산
df['Vehicle_Age'] = current_year - df['model_year']
# 연간 평균 주행 거리 계산
df['Mileage_per_Year'] = df['milage'] / df['Vehicle_Age']
# 차량 나이별 평균 주행 거리
df['milage_with_age'] = df.groupby('Vehicle_Age')['milage'].transform('mean')
# 차량 나이별 평균 연간 주행 거리
df['Mileage_per_Year_with_age'] = df.groupby('Vehicle_Age')['Mileage_per_Year'].transform('mean')
# 럭셔리 브랜드 여부 계산
luxury_brands = ['Mercedes-Benz', 'BMW', 'Audi', 'Porsche', 'Land',
'Lexus', 'Jaguar', 'Bentley', 'Maserati', 'Lamborghini',
'Rolls-Royce', 'Ferrari', 'McLaren', 'Aston', 'Maybach']
df['Is_Luxury_Brand'] = df['brand'].apply(lambda x: 1 if x in luxury_brands else 0)
return df
train = extract_features(train)
test = extract_features(test)
- 결측치 확인 및 처리
cat_c = ['brand','model','fuel_type','engine','transmission','ext_col','int_col','accident','clean_title']
re_ = ['model','engine','transmission','ext_col','int_col']
for d in cat_c:
print(f'{d}의 결측 수:',train[d].isna().sum())
- column별 빈도 확인
import pandas as pd
import matplotlib.pyplot as plt
tar_col = 'brand'
plt.bar(train[tar_col].value_counts().index, train[tar_col].value_counts().values)
tar_col = 'engine'
plt.bar(train[tar_col].value_counts().index, train[tar_col].value_counts().values)
- 범주형 데이터의 카테고리화
def update(df):
t = 100 # 빈도 임계값(threshold)
# 데이터셋에서 전처리할 모든 범주형 열의 리스트
cat_c = ['brand','model','fuel_type','engine','transmission','ext_col','int_col','accident','clean_title']
# 빈도가 낮은 범주를 noise로 대체"할 열의 리스트
re_ = ['model','engine','transmission','ext_col','int_col']
# 빈도 기반 처리 수행 -> 분산값이 커질까봐??
for col in re_:
df.loc[df[col].value_counts(dropna=False)[df[col]].values < t, col] = "noise" # dropna=False?? 결측값을 포함해서 계산? 결측값이 많다면 그것또한 의미가 있다고 판단?
for col in cat_c:
df[col] = df[col].fillna('missing') # 결측 처리 -> 근데 이럴꺼면 위에서 왜 dropna=False를 한거지?
df[col] = df[col].astype('category') # 카테고리 type?? 모델 학습 성능이 향상된다고 하는데....음... 사실 처음봄
return df
train = update(train)
test = update(test)
X = train.drop('price', axis=1) # 입력 변수
y = train['price'] # 목표 변수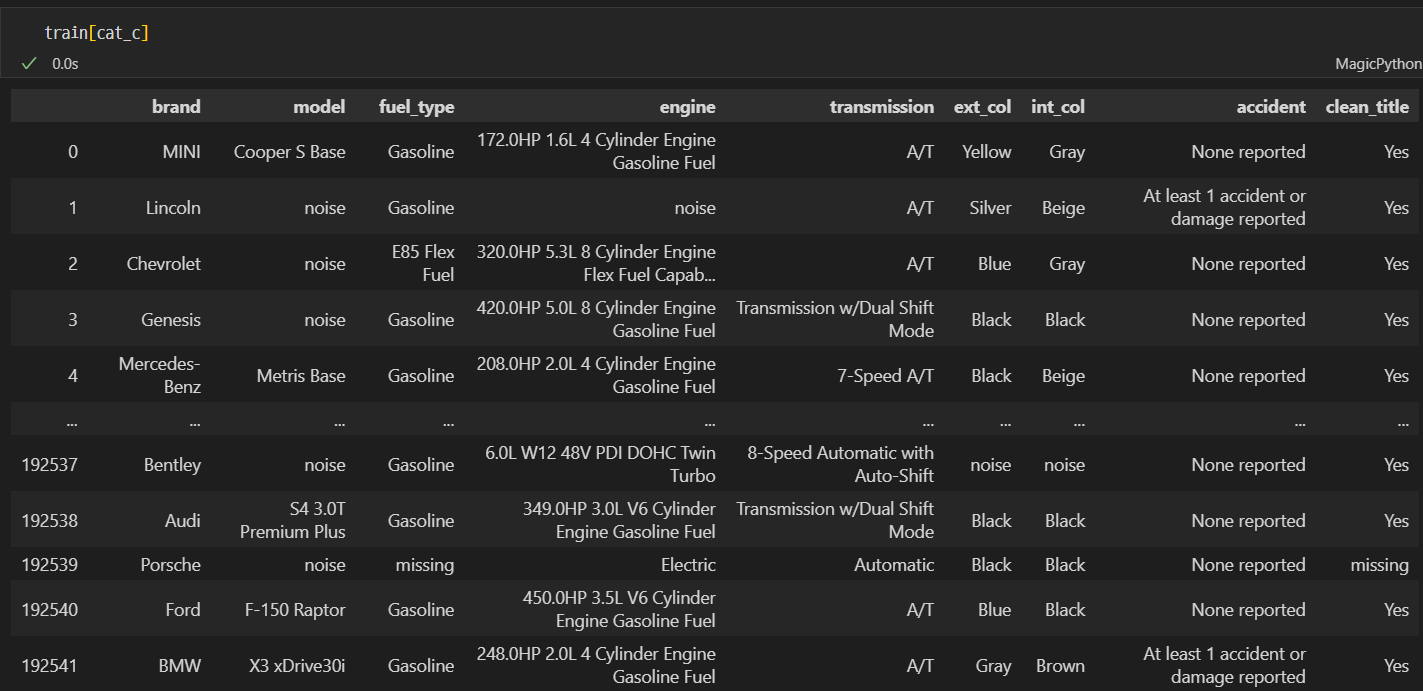
- 모델 학습
import numpy as np
import lightgbm as lgb
from catboost import CatBoostRegressor, Pool
from sklearn.metrics import mean_squared_error
from sklearn.model_selection import KFold
# LightGBM 콜백 설정
callbacks = [
log_evaluation(period=300), # 300번 반복마다 학습 로그 출력
early_stopping(stopping_rounds=200) # 성능이 개선되지 않으면 200번 반복 후 학습 종료 or 200번 동안 개선되지 않으면 종료
]
# 학습 데이터에서 범주형 열을 자동으로 감지
cat_cols = train.select_dtypes(include=['object', 'category']).columns.tolist()
print(f"cat_cols--------{cat_cols}") # 선택된 범주형 열 출력
# OOF 예측 및 K-Fold 교차 검증 함수 정의
def get_MAE_oof(df, target, lgb_params, cat_params=None, model_type='LGBM'):
"""
OOF 예측 및 K-Fold 교차 검증을 통해 LightGBM 또는 CatBoost 모델을 학습하고 평가합니다.
- df: 입력 데이터프레임
- target: 목표 변수
- lgb_params: LightGBM 하이퍼파라미터
- cat_params: CatBoost 하이퍼파라미터 (기본값: None)
- model_type: 사용할 모델 유형 ('LGBM' 또는 'CAT')
"""
# 초기화
oof_predictions = np.zeros(len(df)) # OOF 예측값을 저장할 배열
kf = KFold(n_splits=5, shuffle=True, random_state=1) # 5-Fold 교차 검증
models = [] # 각 Fold의 학습된 모델을 저장
rmse_scores = [] # 각 Fold의 RMSE를 저장
# K-Fold 교차 검증 반복
for fold, (train_idx, val_idx) in enumerate(kf.split(df)):
print(f"Training fold {fold + 1}/{5} with {model_type}")
# 학습 및 검증 데이터를 분리
X_train, X_val = df.iloc[train_idx], df.iloc[val_idx]
y_train, y_val = target.iloc[train_idx], target.iloc[val_idx]
# LightGBM 학습
if model_type == 'LGBM':
# LightGBM 데이터 생성
train_data = lgb.Dataset(X_train, label=y_train)
val_data = lgb.Dataset(X_val, label=y_val, reference=train_data)
# LightGBM 모델 학습
model = lgb.train(
lgb_params, # LightGBM 하이퍼파라미터
train_data, # 학습 데이터
valid_sets=[train_data, val_data], # 학습/검증 데이터
valid_names=['train', 'valid'], # 데이터 이름
callbacks=callbacks # 콜백 설정
)
# CatBoost 학습
elif model_type == 'CAT':
# CatBoost 데이터 생성
train_data = Pool(data=X_train, label=y_train, cat_features=cat_cols)
val_data = Pool(data=X_val, label=y_val, cat_features=cat_cols)
# CatBoost 모델 학습
model = CatBoostRegressor(**cat_params) # CatBoost 하이퍼파라미터
model.fit(
train_data, # 학습 데이터
eval_set=val_data, # 검증 데이터
verbose=150, # 학습 로그 출력 주기
early_stopping_rounds=200 # 조기 종료 기준
)
# 학습된 모델 저장
models.append(model)
# 검증 데이터 예측 및 RMSE 계산
pred = model.predict(X_val) # 검증 데이터 예측
rmse = np.sqrt(mean_squared_error(y_val, pred)) # RMSE 계산
rmse_scores.append(rmse) # RMSE 저장
print(f'{model_type} Fold RMSE: {rmse}')
# OOF 예측값 저장
oof_predictions[val_idx] = pred
# 전체 Fold 평균 RMSE 출력
print(f'Mean RMSE: {np.mean(rmse_scores)}')
return oof_predictions, models
# 1. MAE 기반 LightGBM 모델 학습 및 특성 생성
lgb_params = {'objective': 'MAE', 'n_estimators': 1000, 'random_state': 1} # MAE 기반 하이퍼파라미터
oof_predictions_lgbm, models_lgbm = get_MAE_oof(X, y, lgb_params, model_type='LGBM') # OOF 예측 및 모델 학습
X['LGBM_MAE'] = oof_predictions_lgbm # MAE 기반 OOF 예측값을 새로운 특성으로 추가
# 테스트 데이터에 대해 MAE 기반 예측 수행
LGBM_preds = np.zeros(len(test)) # 초기화
for model in models_lgbm:
LGBM_preds += model.predict(test) / len(models_lgbm) # 테스트 데이터 예측 및 평균화
test['LGBM_MAE'] = LGBM_preds # 테스트 데이터에 새로운 특성 추가
# 2. MSE 기반 LightGBM 모델 학습 및 특성 생성
lgb_params = {'objective': 'MSE', 'n_estimators': 1000, 'random_state': 1} # MSE 기반 하이퍼파라미터
oof_predictions_lgbm, models_lgbm = get_MAE_oof(X, y, lgb_params, model_type='LGBM') # OOF 예측 및 모델 학습
X['LGBM_MSE_diff'] = oof_predictions_lgbm - X['LGBM_MAE'] # MAE 예측값과의 차이를 새로운 특성으로 추가
# 테스트 데이터에 대해 MSE 기반 예측 수행
LGBM_preds = np.zeros(len(test)) # 초기화
for model in models_lgbm:
LGBM_preds += model.predict(test) / len(models_lgbm) # 테스트 데이터 예측 및 평균화
test['LGBM_MSE_diff'] = LGBM_preds - test['LGBM_MAE'] # MAE 예측값과의 차이를 새로운 특성으로 추가
# 테스트 데이터 확인
test.head() # 생성된 특성 확인
- Autogluon을 사용한 fit
# AutoGluon은 하나의 데이터프레임에 입력 변수와 목표 변수를 함께 포함하는 구조를 사용
X['price'] = y
predictor = TabularPredictor(label='price', # 목표변수 지정
eval_metric='rmse', # 평가 지표 RMSE 사용
problem_type='regression') # 문제 유형을 회귀로 설정
predictor.fit(X,
presets='best_quality', # 더 많은 알고리즘과 하이퍼파라미터 탐색을 수행하므로 시간이 오래 걸릴 수 있음
time_limit=3600*1, # 최대 학습 시간(1시간) 설정, 초과하면 현재까지 학습된 모델 중 최고의 모델을 반환
verbosity=2, # 학습 중 로그 출력 수준 설정(2는 중간 수준의 출력)
num_gpus=1, # GPU가 사용 가능하다면 num_gpus=1로 설정해 학습 속도를 높일 수 있음, CPU 사용시 0
included_model_types=['GBM', 'CAT']) # 포함할 모델 유형으로 Gradient Boosting Machines(GBM)과 CatBoost(CAT)를 지정
- 상위 결과와 혼합
# AutoGluon으로 학습된 모델을 사용하여 테스트 데이터에 대한 예측 수행
y_pred = predictor.predict(test)
# Kaggle 상위권 블렌드 결과 파일 로드
# submission_9.csv 파일의 url : https://www.kaggle.com/code/aryagokh/top-5-blended-car-prices/output?select=submission_9.csv
sub_blend = pd.read_csv(f'{data_path}/submission_9.csv')
# Kaggle에서 제공된 샘플 제출 파일 로드
sample_sub = pd.read_csv(f'{data_path}/sample_submission.csv')
# AutoGluon 예측 결과와 상위권 결과를 혼합
# 혼합 비율: AutoGluon 예측 결과(55%), 상위권 결과(45%) -> 조정 가능
sample_sub['price'] = y_pred * 0.55 + sub_blend['price'] * 0.45
# 혼합된 결과를 'submission.csv' 파일로 저장
sample_sub.to_csv(f"{data_path}/submission.csv", index=False)
# 최종 제출 파일의 상위 5개 행을 출력
sample_sub.head()
- Lesson Learned
Autogluon이라는 새로운 방식의 모델을 사용해 볼 수 있었고, 회귀분석의 다양한 모델을 확인하며 catboost등 이전에 사용해보지 못했던 모델들을 통해 회귀분석의 새로운 분석방식을 습득함
'kaggle study' 카테고리의 다른 글
| Loan Approval Prediction (2) | 2024.12.13 |
|---|---|
| Big Data Derby 2022 (3) | 2024.12.05 |
| Data Science and MLOps Landscape in Industry (0) | 2024.12.03 |


